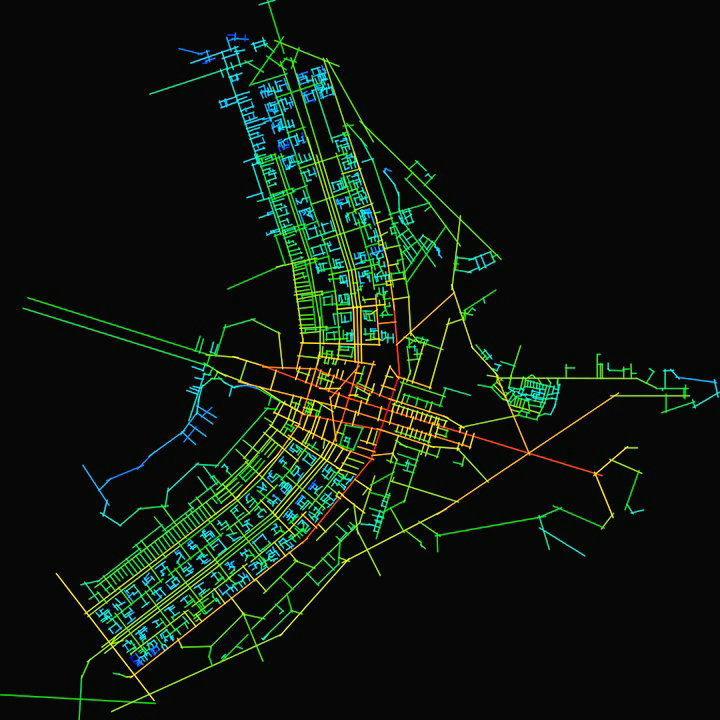
The term space syntax encompasses a set of theories and techniques for the analysis of spatial configurations. It was conceived by Bill Hillier, Julienne Hanson and colleagues at The Bartlett, University College London in the late 1970s to early 1980s as a tool to help urban planners simulate the likely social effects of their designs.
Thesis
The general idea is that spaces can be broken down into components, analyzed as networks of choices, then represented as maps and graphs that describe the relative connectivity and integration of those spaces. It rests on three basic conceptions of space:
an isovist (popularised by Michael Benedikt at University of Texas), or viewshed or visibility polygon, the field of view from any particular point
axial space (idea popularized by Bill Hillier at UCL), a straight sight-line and possible path
convex space (popularized by John Peponis, and his collaborators at Georgia Tech), an occupiable void where, if imagined as a wireframe diagram, no line between two of its points goes outside its perimeter: all points within the polygon are visible to all other points within the polygon.
The three most popular ways of analysing a street network are Integration, Choice and Depth Distance.
Integration measures how many turns have to be made from a street segment to reach all other street segments in the network, using shortest paths. If the number of turns required for reaching all segments in the graph is analyzed, the analysis is said to measure integration at radius ‘n’. The first intersecting segment requires only one turn, the second two turns and so on. The street segments that require the fewest turns to reach all other streets are called ‘most integrated’ and are usually represented with hotter colors, such as red or yellow. Integration can also be analyzed in local scale instead of the scale of the whole network. In the case of radius 4, for instance, only four turns are counted departing from each street segment.
Theoretically, the integration measure shows the cognitive complexity of reaching a street, and is often argued to ‘predict’ the pedestrian use of a street: the easier it is to reach a street, the more popular it should be. While there is some evidence of this being true, the method is biased towards long, straight streets that intersect with lots of other streets. Such streets, as Oxford Street in London, come out as especially strongly integrated. However, a slightly curvy street of the same length would typically be segmented into individual straight segments, not counted as a single line, which makes curvy streets appear less integrated in the analysis.
The Choice measure is easiest to understand as a ‘water-flow’ in the street network. Imagine that each street segment is given an initial load of one unit of water, which then starts pours from the starting street segment to all segments that successively connect to it. Each time an intersection appears, the remaining value of flow is divided equally amongst the splitting streets, until all the other street segments in the graph are reached. For instance, at the first intersection with a single other street, the initial value of one is split into two remaining values of one half, and allocated to the two intersecting street segments. Moving further down, the remaining one half value is again split among the intersecting streets and so on. When the same procedure has been conducted using each segment as a starting point for the initial value of one, a graph of final values appears. The streets with the highest total values of accumulated flow are said to have the highest choice values.
Like Integration, Choice analysis can be restricted to limited local radii, for instance 400m, 800m, 1600m. Interpreting Choice analysis is trickier than Integration. Space syntax argues that these values often predict the car traffic flow of streets, but, strictly speaking, Choice analysis can also be thought to represent the number of intersections that need to be crossed to reach a street. However, since flow values are divided (not subtracted) at each intersection, the output shows an exponential distribution. It is considered best to take a log of base two of the final values in order to get a more accurate picture.
Depth Distance is the most intuitive of the analysis methods. It explains the linear distance from the center point of each street segment to the center points of all the other segments. If every segment is successively chosen as a starting point, a graph of accumulative final values is achieved. The streets with lowest Depth Distance values are said to be nearest to all the other streets. Again, the search radius can be limited to any distance.
Applications
From these components it is thought to be possible to quantify and describe how easily navigable any space is, useful for the design of museums, airports, hospitals, and other settings where wayfinding is a significant issue. Space syntax has also been applied to predict the correlation between spatial layouts and social effects such as crime, traffic flow, and sales per unit area.
History
Space syntax has grown to become a tool used around the world in a variety of research areas and design applications in architecture, urban design, planning, transport and interior design. In general, the analysis uses one of many software programs that allow researchers to analyse graphs of one (or more) of the primary spatial components.
Over the past decade, Space syntax techniques have been used for research in archaeology, information technology, urban and human geography, and anthropology. Since 1997, the Space syntax community has held biennial conferences, and many journal papers have been published on the subject, chiefly in Environment and Planning B.
Criticism
Space syntax’s mathematical reliability has recently come under scrutiny because of a number of paradoxes that arise under certain geometric configurations. These paradoxes have been highlighted by Carlo Ratti at the Massachusetts Institute of Technology, but denied in a passionate academic exchange with Bill Hillier and Alan Penn [2004]. There have been moves to return to combine space syntax with more traditional transport engineering models, using intersections as nodes and constructing visibility graphs to link them, by researchers including Bin Jiang, Valerio Cutini and Michael Batty. Recently there has also been research development that combines space syntax with geographic accessibility analysis in GIS, such as the place syntax-models developed by the research group Spatial Analysis and Design at the Royal Institute of Technology in Stockholm, Sweden. A series of http://journals.sagepub.com/doi/abs/10.1068/b32045 interdisciplinary works published from 2006 by Vito Latora, Sergio Porta and colleagues, proposing a network approach to street centrality analysis and design, have highlighted Space Syntax’ contribution to decades of previous studies in the physics of spatial complex networks.
Source From Wikipedia