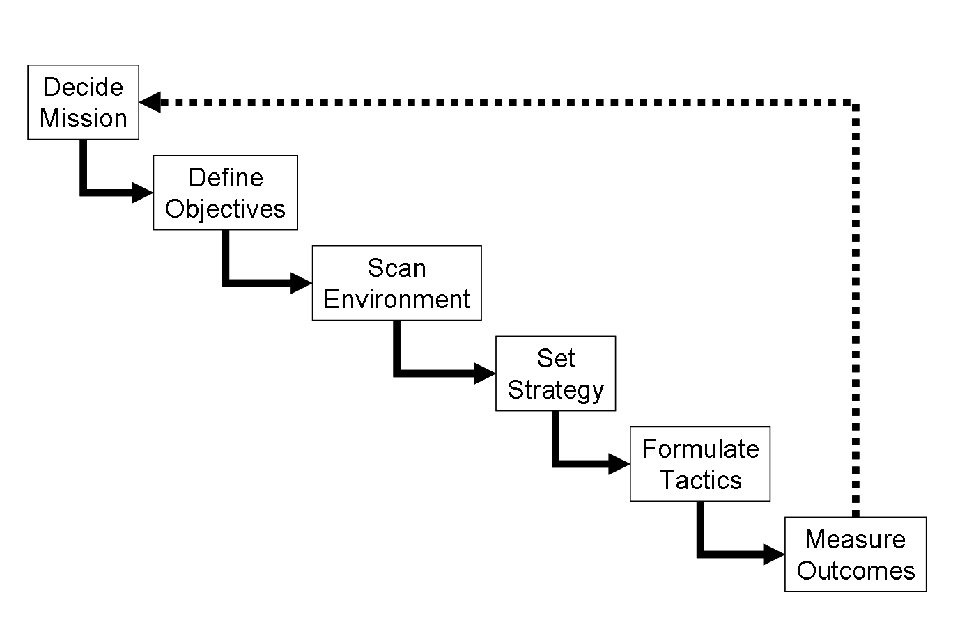
オートプランニングとスケジューリングは、単にAIプランニングと呼ばれることもありますが、一般的にインテリジェントエージェント、自律型ロボット、無人車両が実行する戦略やアクションシーケンスの実現に関係する人工知能の一分野です。 従来の制御および分類の問題とは異なり、ソリューションは複雑であり、多次元空間で発見および最適化する必要があります。 計画は意思決定理論にも関連しています。
使用可能なモデルがある既知の環境では、計画をオフラインで行うことができます。 ソリューションは実行前に見つけて評価することができます。 動的に未知の環境では、戦略はしばしばオンラインで修正する必要があります。 モデルと政策を適合させなければならない。 通常、ソリューションは人工知能で一般的に見られる反復試行錯誤プロセスに頼っています。 これには、動的プログラミング、強化学習、組み合わせ最適化が含まれます。 計画とスケジューリングを記述するために使用される言語は、しばしばアクション言語と呼ばれます。
概要
世界の可能な初期状態の説明、望ましい目標の記述、および可能なアクションのセットの記述が与えられれば、計画問題は保証された計画を合成することである(初期状態のいずれかに適用される場合)所望の目標を含む状態を生成する(このような状態を目標状態と呼ぶ)。
計画の難しさは、使用される仮定の単純化に依存している。 いくつかのクラスの計画問題は、問題がいくつかの次元で持つ特性によって識別することができます。
アクションは決定的か非決定的か? 非決定的な行動については、関連する確率は利用可能であるか?
状態変数は離散か連続か? それらが離散的である場合、有限個の可能な値しか持たないのか?
現在の状態を明白に観察できるか? 完全な観測可能性と部分的な観測可能性があります。
有限または任意の初期状態はいくつあるか?
行動には時間がありますか?
複数のアクションを同時に実行できますか、または同時に実行できるアクションは1つだけですか?
指定された目標状態に到達する、または報酬機能を最大にする計画の目的は?
エージェントは1人だけですか、複数のエージェントがいますか? 代理人は協力的か利己的か? すべてのエージェントが独自のプランを個別に構築するのか、すべてのエージェントが一元的に計画を立てるのか?
可能な限り単純な計画問題は、古典計画問題として知られています。
固有の既知の初期状態、
無期限の行動、
決定論的な行動、
一度に1つしか取ることができない、
単一のエージェントである。
初期状態は明白に知られており、すべてのアクションが決定論的なので、一連のアクションの後の世界の状態は正確に予測でき、観察可能性の問題は古典的計画にとっては無関係です。
さらに、計画はアクションのシーケンスとして定義することができます。なぜなら、どのアクションが必要になるかは常に事前に分かっているからです。
非決定的なアクションまたはエージェントの制御外の他のイベントでは、実行可能な実行がツリーを形成し、ツリーの各ノードに対して適切なアクションを決定する必要があります。
離散時間マルコフ決定プロセス(MDP)は、以下の問題を計画しています。
無期限の行動、
確率を伴う非決定論的行動、
完全な観測可能性、
報酬関数の最大化、
単一のエージェントである。
完全な観測可能性が部分観測可能性に置き換えられるとき、計画は部分的に観測可能なマルコフ決定プロセス(POMDP)に対応する。
複数のエージェントが存在する場合、我々はゲーム理論に密接に関連したマルチエージェント計画を持っています。
ドメイン非依存計画
AI計画では、計画者は通常、ドメインモデル(ドメインをモデル化する一連の可能なアクションの説明)と、初期状態と目標で指定された特定の問題を入力します。指定された入力ドメイン。 そのようなプランナは、広範囲のドメインから計画問題を解決できるという事実を強調するために、「ドメイン独立」と呼ばれています。 ドメインの典型的な例は、ブロックスタッキング、ロジスティクス、ワークフロー管理、ロボットタスク計画です。 したがって、単一ドメイン独立プランナを使用して、これらのさまざまなドメインのすべてで計画問題を解決することができます。 一方、ルートプランナはドメイン固有のプランナの典型です。
計画ドメインのモデリング言語
STRIPSおよび古典計画のPDDLなど、計画ドメインおよび特定の計画上の問題を表すために最も一般的に使用される言語は、状態変数に基づいています。 各可能な状態は状態変数への値の割り当てであり、アクションは状態変数の値がどのように変化するかを決定します。 状態変数の集合は、集合内で指数関数的な大きさを有する状態空間を誘発するので、他の多くの計算問題と同様に、計画は次元の呪縛と組合せ爆発に苦しんでいる。
計画問題を記述するための代替言語は、一連のタスクが与えられ、各タスクはプリミティブアクションによって実現されるか、または他のタスクのセットに分解される階層的タスクネットワークのものである。 より現実的なアプリケーションでは、状態変数によってタスクネットワークの記述が簡素化されますが、これには必ずしも状態変数が含まれるわけではありません。
計画のためのアルゴリズム
古典的な計画
順方向連鎖状態空間探索、おそらくヒューリスティックで強化
(STRIPS、graphplanを参照してください)
部分オーダー計画
古典的な計画
伝統的な計画は、次の2つの前提に基づいています。
行動の決定論。 たとえば、「テーブルにキューブを置く」というアクションは確定的です。 それを実行することによって、ある状態から別の状態に移動します。 逆に、可能性のある値があるので、「サイコロを振る」は決定的ではありません。 「サイコロを振る」アクションは従来の計画の範囲には含まれません。
完璧な観察。 エージェント(ロボット、プログラムなど)は、世界の状態を完全に知っています。
古典的な計画では、一連の行動(例えば、「パンを取る」、「水を入れる」、「パスタを入れる」、「火をつける」、「手を伸ばす」、火災”)。 A *アルゴリズムは、単純化のため入門コースでよく使用される古典的な計画アルゴリズムの典型的な例です。 クラシックプランナーで使用されるアルゴリズムテクニックをいくつか紹介します。
状態空間における順方向探索:発見的探索計画(HSP)アルゴリズム、早送りアルゴリズム(FF)
状態空間における逆探索、
前に計画のスペースで検索、graphplan
計画問題の緩和:最初の問題を解決するのに役立つ計画があるかどうかを知ることがより容易な緩和された問題を計算する
命題論理の公式の充足可能性問題への変換
Bylanderは、1994年に従来の計画がPSPACE完全であることを実証しました。
他の問題への削減
命題充足可能性問題(satplan)に減少する。
モデル検査への削減 – どちらも本質的に状態空間を横断する問題であり、古典的計画問題はモデル検査問題のサブクラスに対応する。
時間計画
時間計画は、古典計画と同様の方法で解決できます。 主な違いは、複数の時間的に重複するアクションが同時に実行される可能性があるため、状態の定義には現在の絶対時間に関する情報と各アクティブなアクションの実行がどの程度進んでいるかが含まれている必要があります。 さらに、合理的またはリアルタイムの計画において、整数時間の古典的計画または計画とは異なり、状態空間は無限大であってもよい。 時間計画はスケジューリング問題と密接に関連しています。 時間計画は、時限オートマトンの観点からも理解することができます。
確率的計画
確率的計画は、状態空間が十分に小さいときに、値の繰り返しやポリシーの反復などの反復的な方法で解決できます。 部分的な可観測性では、反復的な方法で確率的計画が同様に解決されますが、状態の代わりに信念の空間に定義された値関数の表現を使用します。
プリファレンスベースの計画
優先順位ベースの計画では、目的は計画を作成するだけでなく、ユーザー指定のプリファレンスを満たすことです。 例えば、MDPに対応するより一般的な報酬ベースの計画との違いは、必ずしも正確な数値を有するとは限らない。
条件付き計画
決定論的計画は、階層プランナであるSTRIPS計画システムで導入されました。 アクション名は順番に並べられており、これはロボットの計画です。 階層計画は、自動生成された動作ツリーと比較することができます。 欠点は、通常の動作ツリーは、コンピュータプログラムのように表現力がないことです。 つまり、ビヘイビアグラフの表記にはアクションコマンドが含まれていますが、ループやif-thenステートメントは含まれていません。 条件付き計画は、ボトルネックを克服し、パスカルのような他のプログラミング言語から知られている制御フローと同様の精巧な表記法を導入する。 これはプログラム合成と非常によく似ています。つまり、プランナーがインタプリタによって実行できるソースコードを生成します。
条件付きプランナーの初期の例は、1970年代半ばに導入された「Warplan-C」です。 これまでのところ、問題は、通常のシーケンスとif-then-statementを含む複雑なプランとの違いには答えられませんでした。 実行時の計画の不確実性と関係しています。 計画は、プランナにとって未知のセンサ信号に反応することができるという考え方です。 プランナは、2つの選択肢を事前に生成します。 たとえば、オブジェクトが検出された場合はアクションAが実行され、オブジェクトが見つからない場合はアクションBが実行されます。 条件付き計画の主な利点は、部分計画を処理できることです。 エージェントは最初から最後まですべてを計画する必要はありませんが、問題をチャンクに分割できます。 これは、状態空間を減らし、より複雑な問題を解決するのに役立ちます。
計画システムの導入
ハッブル宇宙望遠鏡は、SPSSと呼ばれる短期間のシステムと、スパイクと呼ばれる長期計画システムを使用しています。
その他のタイプの計画
実際には、古典的な計画の前提はほとんどありません。 これが多くの拡張が登場した理由です。
適合計画
システムが不確実な状態にある適合計画(適合スケジュール)について話しますが、観察は不可能です。 エージェントは現実の世界についての信念を持っています。 これらの問題は、従来の計画と同様の手法で解決されますが、現在の状況の不確実性のために、状態空間が問題の規模で指数関数的である場合は解決されます。 スケジュールに合致する問題の解決策は、一連のアクションです。
不測の事態の計画
環境がセンサによって観測可能な不測の事態計画(偶発的計画)。障害がある可能性があります。 偶発的な計画問題では、計画は、もはや一連の行動ではなく、決定木である。なぜなら、計画の各段階は、古典的計画の場合のように完全に観測可能な状態ではなく状態の集合によって表されるからである。
Rintanenは、分岐が追加された場合(偶発的な計画)には、計画問題がEXPTIME-completeとなることを2004年に実証しました。 連続した計画の特別なケースは、「完全に観測可能かつ非決定論的」という問題FONDによって表されます。 目標がLTLf(有限トレース上の線形時間論理)で指定されている場合、問題は常にLDLfの目的仕様のEXPTIME-complete 16および2EXPTIME-completeです。
さらに、伝統的な計画(すなわち準拠した計画)に不確定性が加わると、それはEXPSPACE -completeになります。 分岐と不確実性の両方を追加すると(準拠と偶発的の両方を計画する)、それは2EXPTIME-completeになります。
確率的計画
Kushmerick et al。 確率的計画を導入した。 彼らの研究では、行動の効果は確率論者によって記述されている。 彼は、「ロボットがブロックを取る」アクションの例を以下のように説明します:ロボットのグリッパが乾いている場合、ロボットは確率0.95のブロックを保持します。 クランプが濡れている場合、ロボットは0.5の確率でブロックを保持する。
これは、マルコフ決定プロセス(MDP)または(一般的なケースでは)部分的に観察可能なマルコフ決定プロセス(POMDP)のためのポリシー生成または戦略の問題につながる。
非線形計画
古典的な計画では、サブゴールが所定の順序で解決されます。 問題は、時には既に構築されているものを破壊することにつながることです。 この現象は、Sussmanの異常として知られています。
個々の裸足が、右靴、左靴、右靴下および左靴下を着用しているのと同じ状態にあると仮定します。 発声の順番で目標を達成しようとするなら、彼は失敗するでしょう。
このタイプの問題を解決するには、必要なときにのみアクション間の順序が固定されている部分的に順序付けされた計画に移行することができます(最新のコミットメントまたはコミットメント計画の最小化)。
前の例では、左靴を置いてから靴下を左に入れた後に行うべきです。 右にも同じ。 一方、左の計画の実行は、右の実行とは無関係です。 したがって、全体計画は部分的に発注されます。
このカテゴリーの問題に対処できる計画者は部分的な注文(POP、NOAHなど)と言われています。
階層計画
一般的に、計画するとき、アクションに関する階層的な情報、すなわち複雑なアクションがどのように分解されるかの記述を持つことができます。 例えば、「コーヒーを提供する」のような複雑なアクションは、「コーヒーを作る」と「コーヒーを持ってくる」という2つの複雑なアクションのシーケンスに分解することができます。 したがって、アクションの記述に加えて、アクションとして階層的な記述を入力するABSTRIPSのようなプランナーが存在します。 たとえば、高いレベルで計画を立ててから、必要に応じて細部に行くことができます(たとえば、ABSTRIPSのように)。 その後、目的は、階層タスクネットワーク(HTN)を使用して記述される。
時間計画
時間計画では、行動時間、行動の開始時、終了時および終了時の条件、行動の開始時および終了時の効果を表現できます。 PDDL 2.1には時間計画が含まれています。 メソッドTLP-GP 1は、グラフを作成し、次にSMTソルバを使用して時間的制約を解決します。 一貫性のない場合のバックトラッキング。 Rintanenは、並行時間計画(同じ並列アクションの複数のインスタンスが可能)がEXPSPACE-completeであることを実証しました。 一方、これらの条件を緩和すれば、従来の計画に自信を持たせることができます。したがって、これらの制約を伴う時間的計画は、PSPACE-completeになります。
一般的な計画
一般的な計画は、いくつかの開始環境で機能する計画を作成することから成ります。
複数エージェント計画
マルチエージェントスケジューリングでは、複数のエージェント(たとえば、複数のロボット)によるタスクの完了を調べます。 計画の作成とその実行は、しばしば分散/分散化されます。 計画の重要な側面は、エージェント間の協力です。 MA-STRIPSと呼ばれるマルチエージェントフレームワークに対するSTRIPSの一般化に依存する中央スケジューリングアルゴリズムも存在する。 アルゴリズムは、エージェント間の調整を管理するために分散されたソルバCSPを使用して分散レンダリングされました。 著者、Nissim、Brafman、およびDomshlakは、エージェントがお互いにほとんどやりとりをしていないとき、彼らのアルゴリズムが中央スケジューリングより優れていることを実験的に検証しました。
マルチエージェントプランニングの主な難点は、エージェントの数が指数関数的であるすべてのアクションの組み合わせによる爆発です。 2011年、JonssonとRovatsosは、この問題に対処するソリューションを提供し、従来の単一エージェント計画に削減しました。 また、アルゴリズムをスケーリングするための更新並列並列化テクニックもあります。
認識論的計画
認識論的計画の問題は、州と行動の記述におけるエージェントの知識を考慮に入れることである。 典型的には、目標は、「エージェントはブロックCがブロックA上にあることをエージェントが知っている」などの認識的モーダル論理の論理式であり、アクションは論理的動的認識のアクションのモデルで表される。 計画上の問題は、その一般性において決定不能である。
目的:
上(A、B)Λ上(B、C)
初期状態 :
(A、表)∧上(B、表)∧上(C、A)Λロック(A)Λロック(B)Λロック(C)♦ディスクロージャー(B)♦ディスクロージャー(C)
利用可能なアクション:
移動(b、x、y)
(b≠y)Λ(x≠y)Λ(b≠y)Λ(b≠y)Λ
追加:Above(b、y)Λ発見(x)
キャンセル:上(b、x)Λ発見(y)
Move_tool(b、x)
(b、x)Λ(b)Λ(b)Λ(b)Λ(b≠x)
追加:上(b、表)Λ発見(x)
キャンセル:上記(b、x)
例
計画の非公式な例。
ターゲット
冷蔵庫にいくつかの果物や野菜がある
初期状態
[空の冷蔵庫、自宅で、スリッパで]
利用可能なアクション(順序付けられていないリスト)
家に帰る、
靴を履く、
車のキーを取る、
車で店に着きます。
徒歩で店に着くと、
家に帰ります、
冷蔵庫に買い物をして、
店に入る、
果物を取る、
野菜を取る、
支払う。
考えられる解決策(順序付きリスト)
[1-靴を履く、2-車のキーを取る、3-家から出る、車で店に行く、5-店に入る、6-果物を取る、7-野菜を取る、8-支払い、 9-家に帰る、冷蔵庫で10-場所で購入する]
もう一つの可能な解決策(順序付けられたリスト):
[1-靴を履く、2-外出する、3-足で店に出る、4-店に入る、5-野菜をとる、6-果物を取る、7-支払いする、8-家に帰す、9-場所で購入する冷蔵庫の中]
結論
この例からわかるように、
解は複数であってもよく、
必然的に、他のものの後に実行されなければならないアクションが存在する可能性があります(私が前にキーを取らなかった場合、私は車で店に到達できません)。
可逆的な行動があるかもしれない(果物や野菜をとる)
複数のアクションや一連の交換可能なアクション(徒歩または車でショップに行く)の場合、最終プランにすべてのアクションが含まれている必要はありません。