Planificación y programación automatizadas.

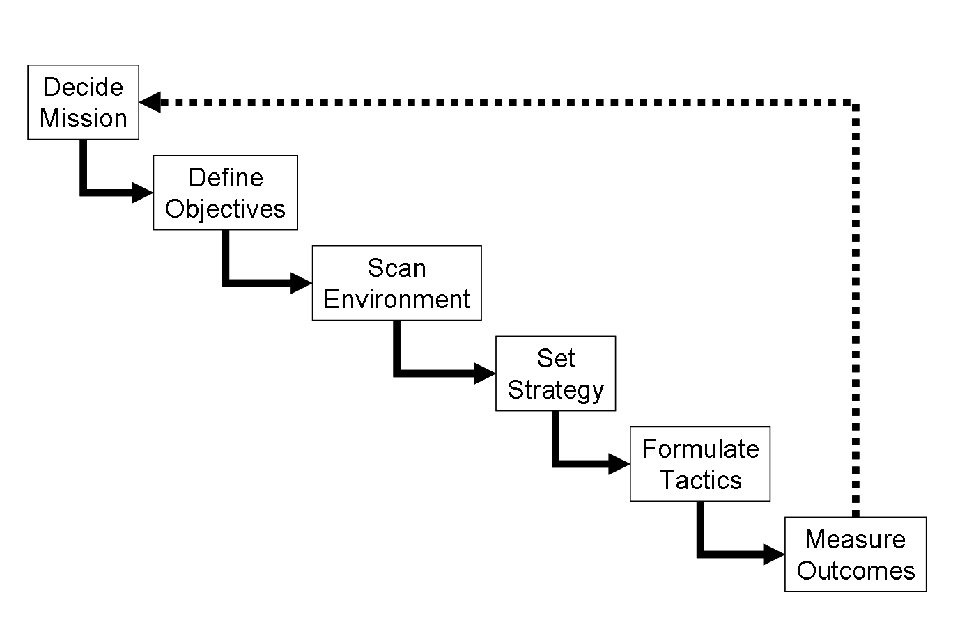
La planificación y programación automatizadas, a veces denotadas simplemente como Planificación de AI, es una rama de la inteligencia artificial que se refiere a la realización de estrategias o secuencias de acción, típicamente para la ejecución por agentes inteligentes, robots autónomos y vehículos no tripulados. A diferencia de los problemas clásicos de control y clasificación, las soluciones son complejas y deben descubrirse y optimizarse en el espacio multidimensional. La planificación también está relacionada con la teoría de la decisión.
En entornos conocidos con modelos disponibles, la planificación se puede hacer fuera de línea. Las soluciones se pueden encontrar y evaluar antes de la ejecución. En entornos dinámicamente desconocidos, la estrategia a menudo necesita ser revisada en línea. Los modelos y políticas deben ser adaptados. Las soluciones generalmente recurren a procesos iterativos de prueba y error comúnmente vistos en inteligencia artificial. Estos incluyen programación dinámica, aprendizaje por refuerzo y optimización combinatoria. Los lenguajes utilizados para describir la planificación y la programación suelen denominarse lenguajes de acción.
Visión general
Dada una descripción de los posibles estados iniciales del mundo, una descripción de los objetivos deseados y una descripción de un conjunto de posibles acciones, el problema de planificación es sintetizar un plan que está garantizado (cuando se aplica a cualquiera de los estados iniciales) para generar un estado que contenga los objetivos deseados (este estado se denomina estado de objetivo).
La dificultad de la planificación depende de los supuestos de simplificación empleados. Se pueden identificar varias clases de problemas de planificación dependiendo de las propiedades que los problemas tienen en varias dimensiones.
¿Son las acciones deterministas o no deterministas? Para acciones no deterministas, ¿están disponibles las probabilidades asociadas?
¿Las variables de estado son discretas o continuas? Si son discretos, ¿tienen solo un número finito de valores posibles?
¿Se puede observar sin ambigüedad el estado actual? Puede haber observabilidad total y observabilidad parcial.
¿Cuántos estados iniciales hay, finitos o arbitrariamente muchos?
¿Las acciones tienen una duración?
¿Se pueden realizar varias acciones al mismo tiempo o solo es posible una acción a la vez?
¿El objetivo de un plan es alcanzar un estado objetivo designado o maximizar una función de recompensa?
¿Hay un solo agente o hay varios agentes? ¿Son los agentes cooperativos o egoístas? ¿Todos los agentes construyen sus propios planes por separado o los planes se construyen de manera central para todos los agentes?
El problema de planificación más simple posible, conocido como el problema de planificación clásica, está determinado por:
un estado inicial único conocido,
acciones sin duración,
acciones deterministas,
que se puede tomar solo una a la vez,
y un solo agente.
Dado que el estado inicial se conoce sin ambigüedad y todas las acciones son deterministas, el estado del mundo después de cualquier secuencia de acciones se puede predecir con precisión, y la cuestión de la observabilidad es irrelevante para la planificación clásica.
Además, los planes pueden definirse como secuencias de acciones, porque siempre se sabe de antemano qué acciones se necesitarán.
Con acciones no deterministas u otros eventos fuera del control del agente, las posibles ejecuciones forman un árbol, y los planes deben determinar las acciones apropiadas para cada nodo del árbol.
Los procesos de decisión de Markov (MDP) en tiempo discreto son problemas de planificación con:
acciones sin duración,
Acciones no deterministas con probabilidades,
observabilidad total,
maximización de una función de recompensa,
y un solo agente.
Cuando se reemplaza la observabilidad total por la observabilidad parcial, la planificación corresponde al proceso de decisión de Markov (POMDP) parcialmente observable.
Si hay más de un agente, tenemos una planificación multiagente, que está estrechamente relacionada con la teoría de juegos.
Dominio de planificación independiente
En AI Planning, los planificadores suelen ingresar un modelo de dominio (una descripción de un conjunto de posibles acciones que modelan el dominio), así como el problema específico que debe resolverse especificado por el estado inicial y el objetivo, en contraste con aquellos en los que no hay Se especificó el dominio de entrada. Tales planificadores se denominan «Dominio independiente» para enfatizar el hecho de que pueden resolver problemas de planificación desde una amplia gama de dominios. Los ejemplos típicos de dominios son el apilamiento de bloques, la logística, la administración del flujo de trabajo y la planificación de tareas de robot. Por lo tanto, se puede utilizar un planificador independiente de un solo dominio para resolver problemas de planificación en todos estos diversos dominios. Por otro lado, un planificador de rutas es típico de un planificador específico de dominio.
Planificación de lenguajes de modelado de dominios
Los idiomas más utilizados para representar dominios de planificación y problemas de planificación específicos, como STRIPS y PDDL para la planificación clásica, se basan en variables de estado. Cada posible estado del mundo es una asignación de valores a las variables de estado, y las acciones determinan cómo cambian los valores de las variables de estado cuando se realiza esa acción. Dado que un conjunto de variables de estado inducen un espacio de estado que tiene un tamaño que es exponencial en el conjunto, la planificación, de manera similar a muchos otros problemas computacionales, sufre la maldición de la dimensionalidad y la explosión combinatoria.
Un lenguaje alternativo para describir los problemas de planificación es el de las redes de tareas jerárquicas, en las que se da un conjunto de tareas, y cada tarea puede realizarse mediante una acción primitiva o descomponerse en un conjunto de otras tareas. Esto no implica necesariamente variables de estado, aunque en aplicaciones más realistas las variables de estado simplifican la descripción de las redes de tareas.
Algoritmos para la planificación.
Planificacion clasica
encadenamiento hacia adelante del estado de búsqueda espacial, posiblemente mejorado con heurísticas
Búsqueda de encadenamiento hacia atrás, posiblemente mejorada por el uso de restricciones de estado (vea STRIPS, graphplan)
planificación de orden parcial
Planificación clásica
La planificación tradicional se basa en dos supuestos:
El determinismo de las acciones. Por ejemplo, la acción «poner un cubo en la mesa» es determinista. Al ejecutarlo, nos movemos de un estado a otro. Por el contrario, «tirar un dado» no es determinista porque hay valores posibles. La acción «lanzar un dado» no está dentro del alcance de la planificación tradicional.
La observación perfecta. El agente (el robot, el programa, etc.) conoce completamente el estado del mundo.
En la planificación clásica, se trata de buscar una secuencia de acciones (por ejemplo, «tomar una sartén», «poner agua», «poner pasta», «encender un fuego», «alcanzar», «para apagar la fuego»). El algoritmo A * es un ejemplo típico de un algoritmo de planificación clásico, utilizado a menudo en cursos de introducción por su simplicidad. Aquí hay algunas técnicas algorítmicas usadas en los planificadores clásicos:
la búsqueda hacia adelante en un espacio de estado: algoritmo de planificación de búsqueda heurística (HSP), algoritmo de avance rápido (FF),
la búsqueda hacia atrás en un espacio de estado,
La búsqueda antes en un espacio de planos, graphplan.
relajación de un problema de planificación: calcular un problema relajado para el cual es más fácil saber si existe un plan que ayude a resolver el problema inicial
La transformación a un problema de satisfacibilidad de una fórmula de lógica proposicional.
Bylander demostró en 1994 que la planificación convencional está completa para PSPACE.
Reducción a otros problemas.
Reducción al problema de satisfacción proposicional (plan).
reducción a la verificación de modelos: ambos son esencialmente problemas para atravesar espacios de estado, y el problema de planificación clásico corresponde a una subclase de problemas de verificación de modelos.
Planificación temporal
La planificación temporal se puede resolver con métodos similares a la planificación clásica. La principal diferencia es que, debido a la posibilidad de varias acciones que se superponen temporalmente con una duración que se toma simultáneamente, la definición de un estado debe incluir información sobre el tiempo absoluto actual y hasta qué punto ha avanzado la ejecución de cada acción activa. Además, en la planificación con tiempo real o racional, el espacio de estado puede ser infinito, a diferencia de la planificación clásica o la planificación con tiempo entero. La planificación temporal está estrechamente relacionada con los problemas de programación. La planificación temporal también se puede entender en términos de autómatas cronometrados.
Planificación probabilística
La planificación probabilística se puede resolver con métodos iterativos como la iteración de valores y la iteración de políticas, cuando el espacio de estado es lo suficientemente pequeño. Con observabilidad parcial, la planificación probabilística se resuelve de manera similar con métodos iterativos, pero utilizando una representación de las funciones de valor definidas para el espacio de creencias en lugar de estados.
Planificación basada en preferencias
En la planificación basada en preferencias, el objetivo no es solo producir un plan sino también satisfacer las preferencias especificadas por el usuario. Una diferencia a la planificación más común basada en la recompensa, por ejemplo, correspondiente a los MDP, las preferencias no necesariamente tienen un valor numérico preciso.
Planificación condicional
La planificación determinista se introdujo con el sistema de planificación STRIPS, que es un planificador jerárquico. Los nombres de acción se ordenan en una secuencia y este es un plan para el robot. La planificación jerárquica se puede comparar con un árbol de comportamiento generado automáticamente. La desventaja es que un árbol de comportamiento normal no es tan expresivo como un programa de computadora. Eso significa que, la notación de un gráfico de comportamiento contiene comandos de acción, pero no bucles ni sentencias if-then. La planificación condicional supera el cuello de botella e introduce una notación elaborada que es similar a un flujo de control, conocido de otros lenguajes de programación como Pascal. Es muy similar a la síntesis de programas, lo que significa que un planificador genera un código fuente que puede ser ejecutado por un intérprete.
Un ejemplo temprano de un planificador condicional es «Warplan-C», que se introdujo a mediados de la década de 1970. Hasta ahora, no se respondía a la pregunta cuál es la diferencia entre una secuencia normal y un plan complicado, que contiene afirmaciones de tipo «si entonces». Tiene que ver con la incertidumbre en el tiempo de ejecución de un plan. La idea es que un plan puede reaccionar a señales de sensores que son desconocidas para el planificador. El planificador genera dos opciones por adelantado. Por ejemplo, si se detectó un objeto, entonces se ejecuta la acción A, si falta un objeto, entonces se ejecuta la acción B. Una ventaja importante de la planificación condicional es la capacidad de manejar planes parciales. Un agente no está obligado a planificar todo desde el principio hasta el final, pero puede dividir el problema en partes. Esto ayuda a reducir el espacio de estado y resuelve problemas mucho más complejos.
Despliegue de sistemas de planificación.
El Telescopio Espacial Hubble utiliza un sistema a corto plazo llamado SPSS y un sistema de planificación a largo plazo llamado Spike.
Otros tipos de planificación.
En la práctica, solo verifica raramente los supuestos de la planificación clásica. Por eso han surgido muchas extensiones.
Planificacion conforme
Hablamos de planificación conforme (cronograma conforme) donde el sistema se encuentra en un estado incierto, pero no es posible hacer observaciones. El agente entonces tiene creencias sobre el mundo real. Estos problemas se resuelven mediante técnicas similares a las de la planificación tradicional, pero donde el espacio de estado es exponencial en el tamaño del problema, debido a la incertidumbre sobre el estado actual. Una solución para un problema de programación conforme es una secuencia de acciones.
Planificación de contingencias
Planificación de contingencia (planificación de contingencia) en la que el entorno es observable por medio de sensores, que pueden ser defectuosos. Para un problema de planificación contingente, un plan ya no es una secuencia de acciones sino un árbol de decisión porque cada etapa del plan está representada por un conjunto de estados en lugar de un solo estado perfectamente observable como en el caso de la planificación clásica.
Rintanen demostró en 2004 que si se agrega la bifurcación (planificación contingente), el problema de planificación se completa a la EXPOTENCIA. Un caso particular de planificación contigua está representado por los problemas FOND: «totalmente observable y no determinista». Si el objetivo se especifica en LTLf (lógica temporal temporal sobre traza finita), el problema siempre es EXPTIME-complete 16 y 2EXPTIME-complete para una especificación de propósito en LDLf.
Si, además, uno agrega incertidumbre a la planificación tradicional (es decir, una planificación compatible), se convierte en EXPSPACE -completo. Si agregamos tanto la bifurcación como la incertidumbre (planificando tanto el cumplimiento como el contingente), se convierte en 2EXPTIME-complete.
Planificación probabilística
Kushmerick et al. Se introdujo la planificación probabilística. En su trabajo, el efecto de las acciones se describe con probabilistas. Da el ejemplo de la acción «el robot toma un bloque» que se describe de la siguiente manera: si la pinza del robot está seca, entonces el robot mantiene el bloque con una probabilidad de 0.95; Si la pinza está mojada, entonces el robot sostiene el bloque con una probabilidad de 0.5.
Esto conduce al problema de la generación de políticas (o estrategia) para un Proceso de Decisión de Markov (MDP) o (en el caso general) un Proceso de Decisión de Markov Parcialmente Observable (POMDP).
Planificación no lineal
La planificación clásica resuelve los subobjetivos en un orden dado. El problema es que a veces conduce a destruir lo que ya se ha construido. Este fenómeno es conocido como la anomalía de Sussman.
Supongamos que un individuo descalzo debe estar en las mismas condiciones en que está usando su zapato derecho, su zapato izquierdo, su calcetín derecho y su calcetín izquierdo. Si busca alcanzar los objetivos en el orden de la expresión, fracasará.
Para resolver este tipo de problema, se puede pasar a planes parcialmente ordenados en los que el orden entre las acciones se fija solo cuando es necesario (compromiso a la última o menos planificación de compromiso).
En el ejemplo anterior, poner el zapato izquierdo se debe hacer después de poner el calcetín a la izquierda. Lo mismo para la derecha. Por otro lado, la ejecución del plan para la izquierda es independiente de la ejecución para la derecha. Por lo tanto, el plan general está parcialmente ordenado.
Los planificadores capaces de manejar esta categoría de problemas se denominan orden parcial (POP, NOAH, etc.).
Planificación jerárquica
Generalmente, cuando se planifica, se puede tener una información jerárquica sobre las acciones, es decir, una descripción de cómo se descomponen las acciones complejas. Por ejemplo, una acción compleja como «servir un café» se puede dividir en la secuencia de dos acciones complejas «preparar un café» y luego «traer café». Por lo tanto, hay planificadores, como ABSTRIPS, que además de la descripción de las acciones, toman como entrada la descripción jerárquica de las acciones. Por ejemplo, se puede comenzar a planificar a un nivel alto y luego bajar en los detalles si es necesario (como lo hace ABSTRIPS, por ejemplo). El objetivo se describe luego utilizando una red de tareas jerárquica (HTN).
Planificación temporal
La planificación del tiempo le permite expresar los tiempos de acción, las condiciones al principio, al final y durante la acción, y los efectos al principio y al final de las acciones. PDDL 2.1 incluye la planificación del tiempo. El método TLP-GP 1 construye un gráfico y luego resuelve las restricciones temporales utilizando un solucionador SMT. Un retroceso en caso de inconsistencia. Rintanen ha demostrado que la planificación de tiempo concurrente (múltiples instancias de la misma acción paralela es posible) se completa con EXPSPACE. Por otro lado, si relajamos estas condiciones, podemos reducirnos a la planificación convencional y, por lo tanto, la planificación temporal con estas restricciones se convierte en PSPACE completa.
Planificacion general
La planificación general consiste en producir un plan que funcione para varios entornos iniciales.
Planificación multiagente
La programación multiagente estudia la finalización de una tarea por múltiples agentes, por ejemplo, múltiples robots. La generación del plan y su ejecución a menudo se distribuyen / descentralizan. Un aspecto importante en los planes es la cooperación entre agentes. También hay un algoritmo de programación centralizada, que se basa en una generalización de STRIPS al marco de múltiples agentes, llamado MA-STRIPS. Luego se distribuyó el algoritmo de representación, utilizando un solucionador CSP distribuido para gestionar la coordinación entre agentes. Los autores, Nissim, Brafman y Domshlak, han verificado experimentalmente que su algoritmo es mejor que la programación centralizada cuando los agentes tienen poca interacción entre sí.
Una dificultad importante en la planificación de múltiples agentes es la explosión combinatoria de todas las acciones, que es exponencial en el número de agentes. En 2011, Jonsson y Rovatsos ofrecen una solución para contrarrestar este problema, lo que se reduce a la planificación clásica de agente único. También hay un uso renovado de técnicas de paralelización para planificar algoritmos a escala.
Planificación epistémica
El problema de planificación epistémica es tener en cuenta el conocimiento de los agentes en la descripción de los estados y las acciones. Típicamente, el objetivo es una fórmula de la lógica modal epistémica, tal como «el agente sabe que el agente b que el bloque C está en el bloque A» y las acciones se representan con modelos de acciones de la lógica dinámica epistémica. El problema de la planificación es indecidible en toda su generalidad.
Objetivo:
Arriba (A, B) Λ Arriba (B, C)
Estado inicial :
[Arriba (A, Tabla) Λ Arriba (B, Tabla) Λ Arriba (C, A) Λ Bloquear (A) Λ Bloquear (B) Λ Bloquear (C) Λ Divulgación (B) Λ Divulgación (C)]
Acciones disponibles:
Mover (b, x, y)
PRE-CONDICIONES: Arriba (b, x) Λ Descubierto (b) Λ Descubierto (y) Λ Bloque (b) Λ Bloque (y) Λ (b ≠ x) Λ (b ≠ y) Λ (x ≠ y)
ADICIONAL: Arriba (b, y) Λ Descubierto (x)
CANCELACIONES: Arriba (b, x) Λ Descubiertas (y)
Move_tool (b, x)
PRECONDICIONES: Arriba (b, x) Λ Descubierto (b) Λ Descubierto (y) Λ Bloque (b) Λ (b ≠ x)
ADICIONAL: Arriba (b, Tabla) Λ Descubierto (x)
CANCELACIONES: Arriba (b, x)
Ejemplo
Ejemplo informal de planificación.
Objetivo
Tener algunas frutas y verduras en la nevera.
Estado inicial
[Nevera vacía, en casa, en zapatillas]
Acciones disponibles (lista desordenada)
salir a casa
usar zapatos,
tomar las llaves del coche,
llegar a la tienda en coche,
llegar a la tienda a pie,
regresar a casa,
colocar las compras en la nevera,
entrar en la tienda,
tomar fruta
tomar verduras,
pagar.
Posible solución (lista ordenada)
[1- use zapatos, 2- lleve las llaves del auto, 3- salga de la casa, 4- llegue a la tienda en auto, 5- ingrese a la tienda, 6- tome fruta, 7- tome vegetales, 8- pague, 9- volver a casa, 10- comprar en la nevera]
Otra posible solución (lista ordenada):
[1- use zapatos, 2- salga, 3- llegue a la tienda a pie, 4- ingrese a la tienda, 5- saque verduras, 6- tome fruta, 7- pague, 8- vaya a casa, 9- compre en lugar en la nevera]
Conclusiones
Del ejemplo podemos ver cómo:
Las soluciones pueden ser múltiples,
pueden estar presentes acciones que deben realizarse, inevitablemente, después de otras (no puedo llegar a la tienda en automóvil si no tomé las llaves antes),
pueden existir acciones que sean reversibles (tomar frutas y verduras),
no es necesario que el plan final contenga todas las acciones en caso de acciones múltiples o secuencias de acciones intercambiables (llegar a la tienda a pie o en auto).